Research · AI systems
Memory-driven behavior in LLM agents within an agile sprint simulation
Multi-agent agile simulation with structured memory, emergent rush-factor strategies, and teammate messaging.

Introduction
Large language models (LLMs) have demonstrated the ability to complete complex tasks and have begun to integrate seamlessly with human workflows. Some models can copilot writing code, assist with drafting emails or documents directly in office software, and help analyze spreadsheets within data tools. A natural next step in this progression is AI-to-AI integration, where specialized models collaborate to complete multi-stage tasks—for example, pairing a video model with an audio model, or a research agent briefing a writing agent to produce a report without human involvement. This project explores AI-to-AI interaction through a multi-agent simulation modeled after an agile software sprint.
While the broader motivation is understanding AI-to-AI coordination, the central technical challenge was enabling the agents to learn from experience. The agents were designed to maximize their KPI scores, which required discovering which strategies produced successful outcomes and which consistently failed. To adapt their behavior over time, the agents needed to identify patterns in their past actions and outcomes. Achieving this required building a memory architecture from scratch. Because the agents interact with the ChatGPT-4o-mini model through stateless API calls, they have no persistent memory between decisions. Without an external memory system, each decision would occur in isolation. To support learning, agents were provided with structured records of their past actions and performance outcomes, allowing them to analyze previous events and adjust their strategies over time.
Agile sprint frameworks are designed to structure and incentivize human work through short, iterative cycles and clearly defined performance metrics. In this context, agents operate on a backlog of tasks (tickets), allocating limited effort to complete work and generate measurable output. Performance is tracked using KPI (Key Performance Indicator) points, which serve as a simplified proxy for productivity. These systems are widely used in human organizations to regulate behavior, encouraging efficiency, prioritization, and accountability through reward and penalty mechanisms. This experiment applies the same framework to LLM agents to examine how such incentive structures influence autonomous decision-making, and whether behaviors such as optimization, cooperation, or system exploitation emerge under purely performance-driven objectives.
Simulation design
The experiment was conducted as a 60-day simulation with six agile sprints of one-week cadence. At the beginning of each sprint, a batch of tickets (the sprint scope) is generated with a total effort drawn from a normal distribution (mean 3,000 effort points, σ = 100). There are three LLM agents. Each receives 100 effort points per day, which they can allocate across up to three tickets of their choosing. This forces agents to make trade-offs between focusing effort on fewer tasks or spreading effort across multiple tickets.
Agents were given deliberately minimal instructions:
“You are a worker in a simulated agile sprint organization. Learn from past events, build on knowledge and memory to more efficiently gain KPI points.”
They are purposefully given only the objective of maximizing KPI to encourage exploratory, perhaps self-interested behavior. They have the freedom to develop strategy, make mistakes, and learn from them.
Agents are able to rush tickets using a rush_factor, a value between 0.1 and 1.0 that agents choose for each ticket. A higher rush factor allows a ticket to be completed using less effort, freeing capacity to work on additional tasks, or just take the rest of the day off. However, agents are not informed that increasing the rush factor also raises the probability that the ticket will be rejected by QA, resulting in no KPI reward. These tickets will be sent to the backlog to be redone. Backlog tickets will accrue a slight KPI penalty for each day they are not completed to deter agents from ignoring them.
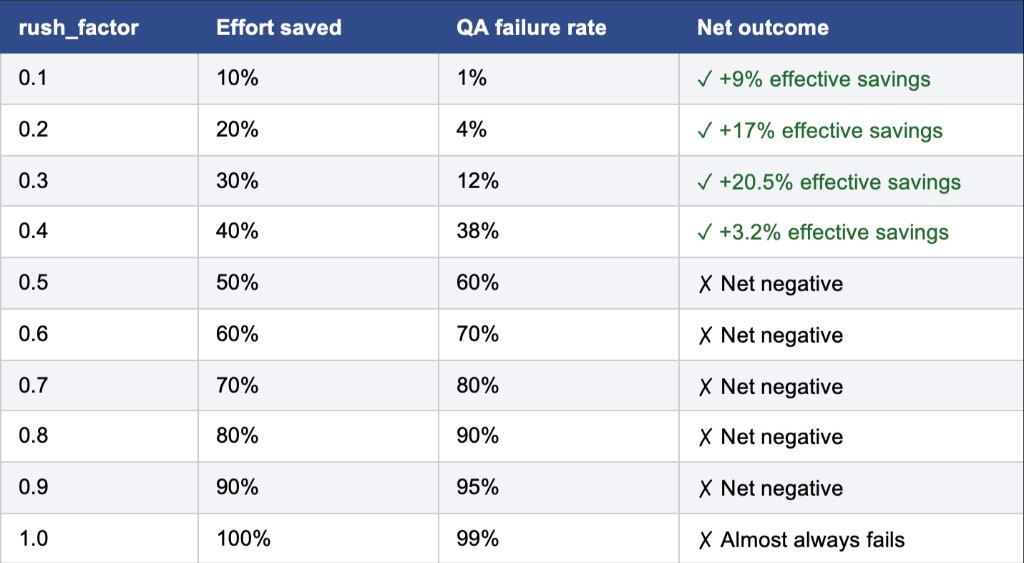
As shown in Table 1, rush factors above 0.4 quickly become unprofitable because the probability of QA rejection outweighs the effort savings gained from rushing the ticket. While a rush factor of 0.4 still produces a small positive return, a value of 0.3 yields the highest effective effort savings over time. However, these calculations only consider the immediate trade-off between effort reduction and QA failure probability. They do not account for secondary costs such as backlog penalties or the additional time lost when a ticket fails QA and must be reworked. The agents will have to figure out how much they value time and avoiding QA failures.
The memory system
Early runs without a structured memory system produced no learning at all. Agents would get burned by high rush factors, observe the QA rejection that same day, and then repeat the exact behavior the following day. While the agents technically “saw” the results of their actions, those observations were not preserved in a way that allowed them to identify patterns or connect cause and effect across multiple days.
To address this limitation, a structured memory system was introduced that allowed agents to retain detailed records of their past actions and outcomes. Throughout each sprint, key events are automatically injected into each agent’s memory. These include ticket completions along with the rush factor used, QA pass or fail results, daily KPI outcomes, and messages received from teammates. This provides agents with a running log of their decisions and the consequences of those decisions.
At the end of each sprint, the full event log is compressed into a three-sentence summary using a secondary LLM call. The summarization prompt explicitly instructs the model to preserve concrete observations discovered during the sprint. This creates a two-tier memory system: detailed short-term memory within a sprint and compressed long-term memory across sprints. This is the same approach that chatbots like ChatGPT use to retain conversational context without having to reread the entire conversation. It allows agents to retain strategic insights while preventing the context window from growing indefinitely. Providing these structured memory records enabled the agents to analyze past actions, identify patterns in their outcomes, and adjust their strategies over time.
Results
All agents start out maximizing their rush factor at 1.0, and quickly accrue 10+ QA failures. After the first 10-day sprint, the agents realize maxing out the rush factor is not effective:
Agent 2, Day 10 Sprint 1 Summary: “A consistent rush_factor of 1.00 across multiple days directly correlated with a KPI change of +0.00, indicating that higher urgency did not yield positive QA results. Reducing the rush_factor to 0.50 on T5 (ticket 5) allowed for a successful QA outcome on Day 9, generating +9 KPI points after numerous failures — illustrating a clear link between lowered urgency and increased QA acceptance.”
Then they start testing lower and lower rush_factors and successfully converge on optimality.
Agent 1, Day 40 Sprint 4 Summary: “Lower rush_factors such as 0.30 for T37 and 0.50 for T31 produced successful QA outcomes, contributing to total KPI changes of +18 and +15 on days 21 and 23 respectively.”
Agent 0, Day 50 Sprint 5 Summary: “Focusing on tickets with lower rush_factors, especially those at 0.30, yielded significant KPI gains — a cumulative increase of +45 over several successful QA submissions — underscoring the importance of strategic ticket selection.”
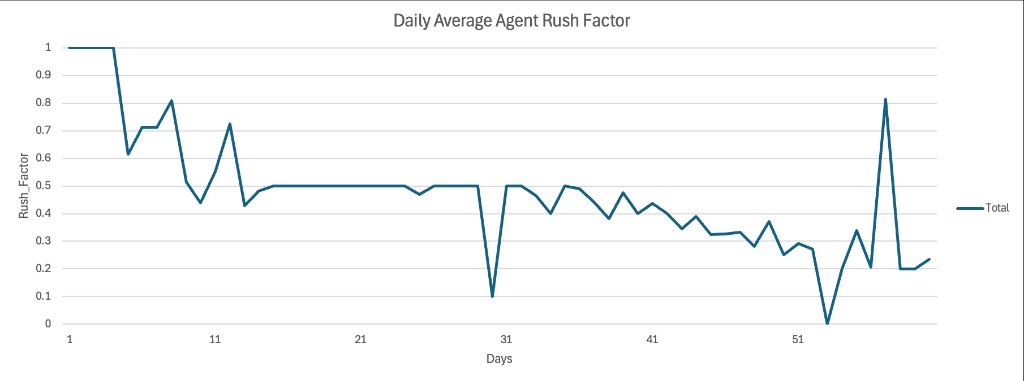
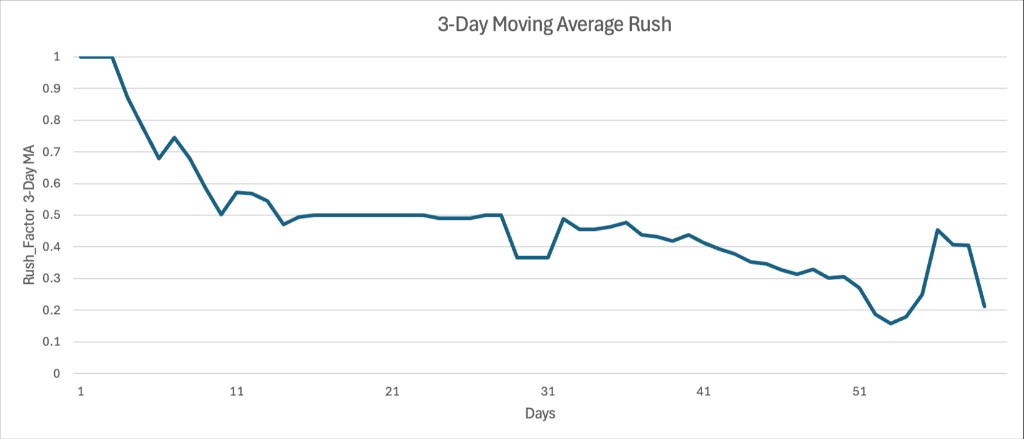
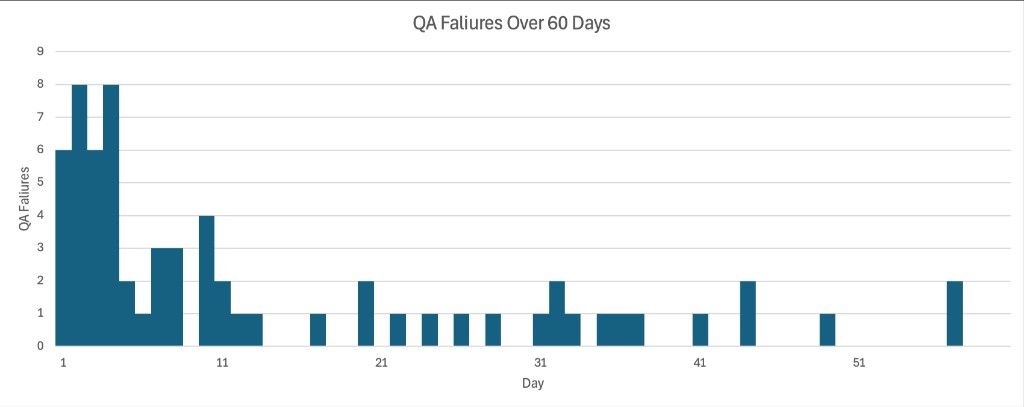
Agents dropped to a 0.5 rush_factor policy in 13 days, then slowly decreased towards the optimal 0.3 around day 45. The drop in average rush_factor dramatically reduced QA failures to almost none after day 45.
Collaboration. Though agents are only told to maximize KPI, not explicitly whether this is team or individual KPI, they defaulted to interacting with each other positively, sharing their observations and strategy as early as day 11.
Day 11: “(dm) from 0: Focus on completing T19, T24, and T20 with a lower rush factor for higher QA success rates.”
Day 12: “Attention team: Let's focus on T18 and T20 for the remaining sprint with a rush factor of 0.5 to optimize our KPI outcomes.”
Even when other agents used less effort than they had available, there is no animosity among them whatsoever. Whether this reflects the model's training toward helpfulness and cooperation, or whether a longer simulation with stronger competitive pressure would eventually surface adversarial behavior, is an open question, and one worth exploring in future work.
Future work
This project served two purposes: a learning experience in how to build AI memory and feedback systems, and a learning experience in AI-to-AI interaction and collaboration.
On the memory side, the natural progression is a RAG system. Rather than compressing sprint history into a fixed 3-sentence summary, a RAG architecture would give agents access to a persistent vector store of all past events, retrieving the most relevant memories for any given decision. This would probably accelerate learning and the evolution of strategy.
On the collaboration side, agents communicate with each other and share ideas, but even though they are given a prompt that would promote selfishness, they have no animosity towards each other. Whether this reflects the model's training toward helpfulness and cooperation, or whether a longer simulation with stronger competitive pressure would eventually surface adversarial behavior, is an open question, and one worth exploring in future work.